Kubernetes is an open-source container orchestration tool or system that is used to automate tasks such as the management, monitoring, scaling, and deployment of containerized applications.
It is used to easily manage several containers (since it can handle grouping of containers), which provides for logical units that can be discovered and managed.
- It places control for the user where the server will host the container. It will control how to launch. So, Kubernetes automates various manual processes.
- Kubernetes manages various clusters at the same time.
- It provides various additional services like management of containers, security, networking, and storage.
- Kubernetes self-monitors the health of nodes and containers.
- With Kubernetes, users can scale resources not only vertically but also horizontally that too easily and quickly.
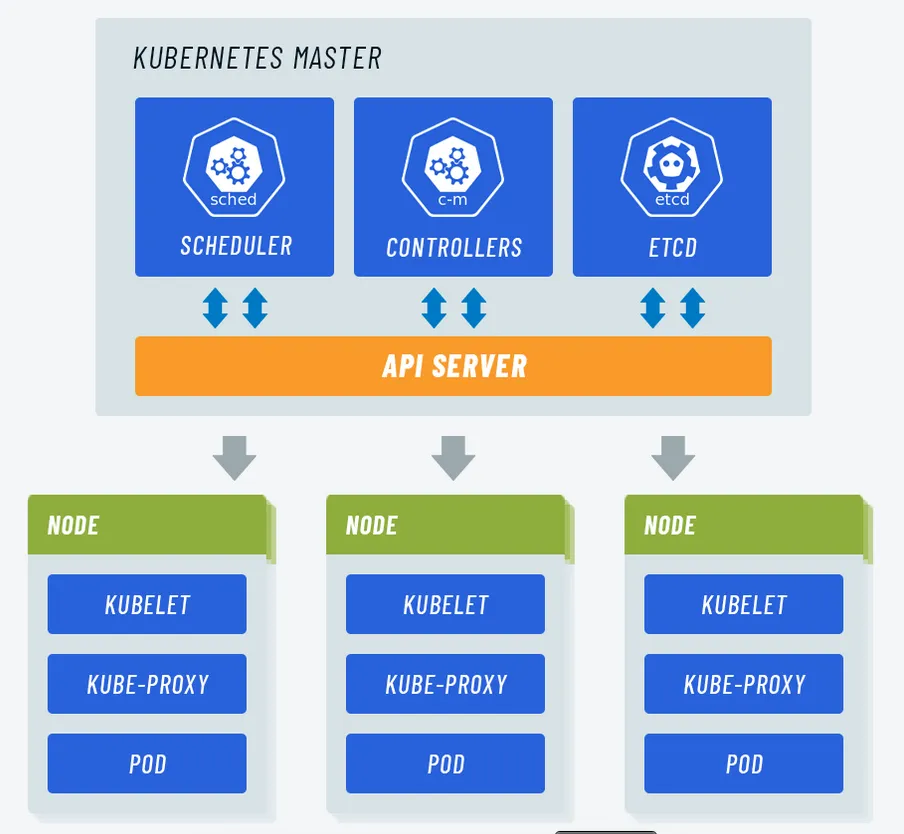
- Master node dignifies the node that controls and manages the set of worker nodes. This kind resembles a cluster in Kubernetes. The nodes are responsible for the cluster management and the API used to configure and manage the resources within the collection. The master nodes of Kubernetes can run with Kubernetes itself, the asset of dedicated pods.
- Node: A node is the smallest fundamental unit of computing hardware. It represents a single machine in a cluster, which could be a physical machine in a data center or a virtual machine from a cloud provider. Each machine can substitute any other machine in a Kubernetes cluster. The master in Kubernetes controls the nodes that have containers.
- Kube-apiserver. This kind validates and provides configuration data for the API objects. It includes pods, services, replication controllers. Also, it provides REST operations and also the frontend of the cluster. This frontend cluster state is shared through which all other component interacts.
- Process runs on Master Node: The Kube-api server process runs on the master node and serves to scale the deployment of more instances.
- Pod: In this Kubernetes interview question, try giving a thorough answer instead of a one-liner. Pods are high-level structures that wrap one or more containers. This is because containers are not run directly in Kubernetes. Containers in the same pod share a local network and the same resources, allowing them to easily communicate with other containers in the same pod as if they were on the same machine, while at the same time maintaining a degree of isolation.
- kube-scheduler: The kube-scheduler assigns nodes to newly created pods.
- Cluster of containers: A cluster of containers is a set of machine elements that are nodes. Clusters initiate specific routes so that the containers running on the nodes can communicate with each other. In Kubernetes, the container engine (not the server of the Kubernetes API) provides hosting for the API server.
- Daemon sets: A Daemon set is a set of pods that runs only once on a host. They are used for host layer attributes like a network or for monitoring a network, which you may not need to run on a host more than once.
- Why Daemon sets: Daemon sets are used because:
- It enables to runs storage platforms like ceph and clusterd on each node.
- Daemon sets run the logs collection on every node such as filebeat or fluentd.
- It performs node monitoring on each and every node.
- Replica set: A Replica set is used to keep replica pods stable. It enables us to specify the available number of identical pods. This can be considered a replacement for the replication controller.
- Stateful sets: The stateful set is a workload API object that is used to manage the stateful application. It can also be used to manage the deployments and scaling the sets of pods. The state information and other data of stateful pods are store in the disk storage, which connects with stateful set.
- Heapster: A Heapster is a performance monitoring and metrics collection system for data collected by the Kublet. This aggregator is natively supported and runs like any other pod within a Kubernetes cluster, which allows it to discover and query usage data from all nodes within the cluster.
- Namespace: Namespaces are used for dividing cluster resources between multiple users. They are meant for environments where there are many users spread across projects or teams and provide a scope of resources.
Initial namespaces:- Default
- Kube – system
- Kube – public
- Controller manager: The controller manager is a daemon that is used for embedding core control loops, garbage collection, and Namespace creation. It enables the running of multiple processes on the master node even though they are compiled to run as a single process.
- Types of controller managers: The primary controller managers that can run on the master node are the endpoints controller, service accounts controller, namespace controller, node controller, token controller, and replication controller.
- etcd: Kubernetes uses etcd as a distributed key-value store for all of its data, including metadata and configuration data, and allows nodes in Kubernetes clusters to read and write data. Although etcd was purposely built for CoreOS, it also works on a variety of operating systems (e.g., Linux, BSB, and OS X) because it is open-source. Etcd represents the state of a cluster at a specific moment in time and is a canonical hub for state management and cluster coordination of a Kubernetes cluster.
- Different types of Kubernetes services include:
- Cluster IP service
- Node Port service
- External Name Creation service and
- Load Balancer service
- ClusterIP: The ClusterIP is the default Kubernetes service that provides a service inside a cluster (with no external access) that other apps inside your cluster can access.
- NodePort: The NodePort service is the most fundamental way to get external traffic directly to your service. It opens a specific port on all Nodes and forwards any traffic sent to this port to the service.
- LoadBalancer: The LoadBalancer service is used to expose services to the internet. A Network load balancer, for example, creates a single IP address that forwards all traffic to your service.
- Ingress network: An ingress is an object that allows users to access your Kubernetes services from outside the Kubernetes cluster. Users can configure the access by creating rules that define which inbound connections reach which services. This is an API object that provides the routing rules to manage the external users’ access to the services in the Kubernetes cluster through HTTPS/ HTTP. With this, users can easily set up the rules for routing traffic without creating a bunch of load balancers or exposing each service to the nodes.
- Cloud controller manager: You must have heard about Public, Private and hybrid clouds. With the help of cloud infrastructure technologies, you can run Kubernetes on them. In the context of Cloud Controller Manager, it is the control panel component that embeds the cloud-specific control logic. This process lets you link the cluster into the cloud provider’s API and separates the elements that interact with the cloud platform from components that only interact with your cluster. This also enables the cloud providers to release the features at a different pace compared to the main Kubernetes project. It is structured using a plugin mechanism and allows various cloud providers to integrate their platforms with Kubernetes.
- Container resource monitoring: This refers to the activity that collects the metrics and tracks the health of containerized applications and microservices environments. It helps to improve health and performance and also makes sure that they operate smoothly.
- Difference between a replica set and a replication controller:
A replication controller. It is a wrapper on a pod. This provides additional functionality to the pods, which offers replicas. It monitors the pods and automatically restarts them if they fail. If the node fails, this controller will respawn all the pods of that node on another node. If the pods die, they won’t be spawned again unless wrapped around a replica set.
Replica Set, on the other hand, is referred to as rs in short. It is told as the next-generation replication controller. This kind of support has some selector types and supports the equality-based and the set-based selectors. It allows filtering by label values and keys. To match the object, they have to satisfy all the specified label constraints. - Headless service: A headless service is used to interface with service discovery mechanisms without being tied to a ClusterIP, therefore allowing you to directly reach pods without having to access them through a proxy. It is useful when neither load balancing nor a single Service IP is required.
- Federated clusters: The aggregation of multiple clusters that treat them as a single logical cluster refers to cluster federation. In this, multiple clusters may be managed as a single cluster. They stay with the assistance of federated groups. Also, users can create various clusters within the data center or cloud and use the federation to control or manage them in one place. You can perform cluster federation by doing the following: Cross cluster that provides the ability to have DNS and Load Balancer with backend from the participating clusters. Users can sync resources across different clusters in order to deploy the same deployment set across the various clusters.
- Kubelet: The kubelet is a service agent that controls and maintains a set of pods by watching for pod specs through the Kubernetes API server. It preserves the pod lifecycle by ensuring that a given set of containers are all running as they should. The kubelet runs on each node and enables the communication between the master and slave nodes. Kubectl is a CLI (command-line interface) that is used to run commands against Kubernetes clusters. As such, it controls the Kubernetes cluster manager through different create and manage commands on the Kubernetes component.
- Standard Kubernetes security measures include defining resource quotas, support for auditing, restriction of etcd access, regular security updates to the environment, network segmentation, definition of strict resource policies, continuous scanning for security vulnerabilities, and using images from authorized repositories.
- Kube-proxy: Kube-proxy is an implementation of a load balancer and network proxy used to support service abstraction with other networking operations. Kube-proxy is responsible for directing traffic to the right container based on IP and the port number of incoming requests.
- List out some important Kubectl commands:
- kubectl annotate
- kubectl cluster-info
- kubectl attach
- kubectl apply
- kubectl config
- kubectl autoscale
- kubectl config current-context
- kubectl config set.


